![[How to hide garbage in Spotify's database and turn it into a quest]](/content/images/2021/06/72a9b81928d88859bf8ffbe1c890dcbf-2-2-2.jpg)
One sleepless night my buddy and I got to talking about Spotify codes.
These are images that can be scanned with an app and take you to the desired track/album/playlist. They were invented so people could share music on social media or offline.

We decided to figure out how Spotify encodes links in these codes.
How do the codes work?
We found out that in addition to the "Share" menu in the app, there is an official Spotify Codes website that generates such codes.
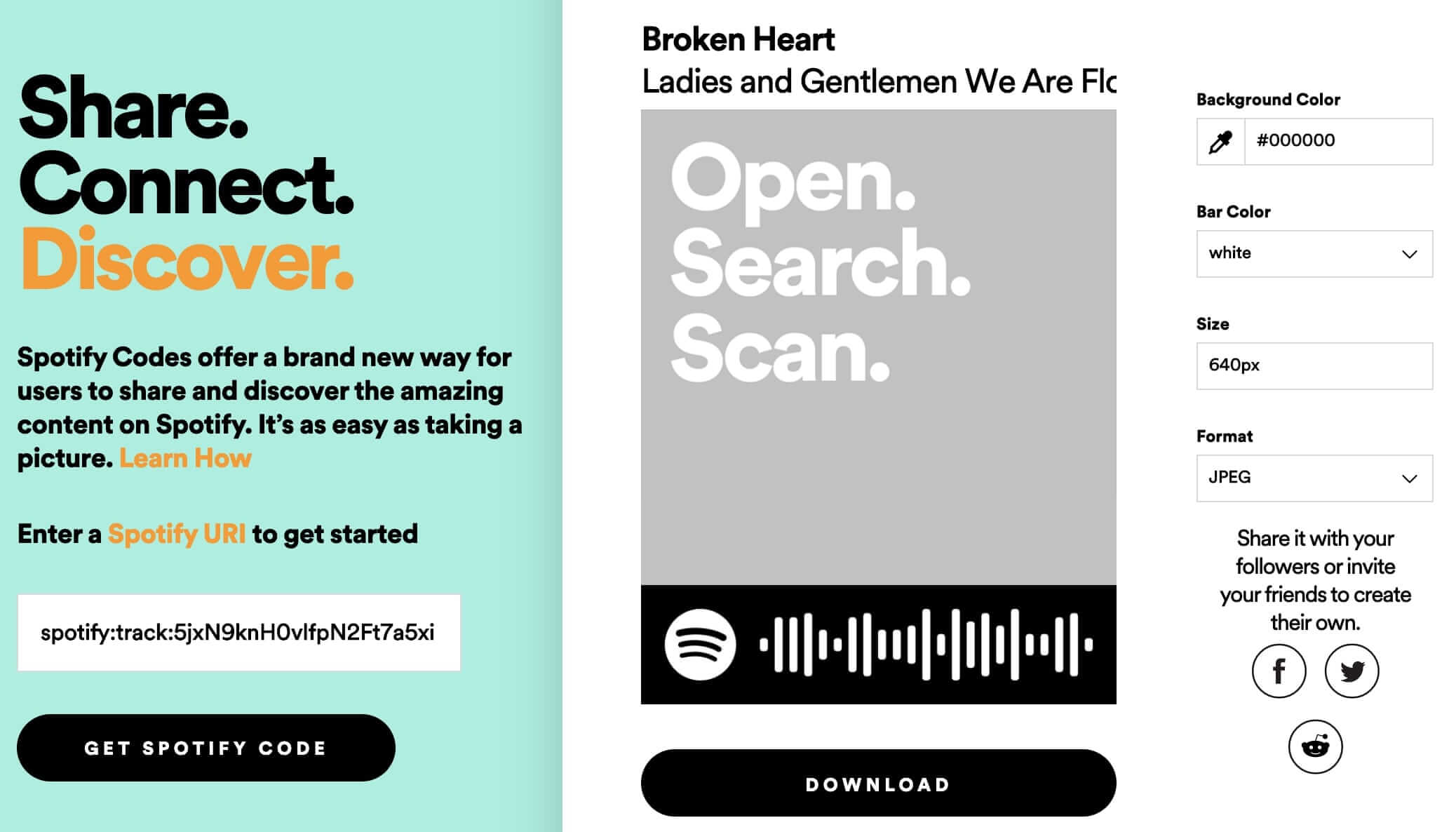
If you copy the link to the image generated by this site, you'll get something like this: https://scannables.scdn.co/uri/plain/jpeg/000000/white/640/spotify:track:5jxN9knH0vlfpN2Ft7a5xi
Perfect! A dynamic link that takes the track ID as input and returns an image with a barcode—just what we need for our experiments.
It's very convenient that the generator can draw codes in SVG as well. This made it easy to understand that there are eight different bar heights.
<rect x="100.00" y="44.50" width="6.71" height="11.00" rx="3.36" ry="3.36" fill="#ffffff"/>
<rect x="112.42" y="27.00" width="6.71" height="46.00" rx="3.36" ry="3.36" fill="#ffffff"/>
<rect x="124.84" y="27.00" width="6.71" height="46.00" rx="3.36" ry="3.36" fill="#ffffff"/>
<rect x="137.27" y="23.50" width="6.71" height="53.00" rx="3.36" ry="3.36" fill="#ffffff"/>
<rect x="149.69" y="37.50" width="6.71" height="25.00" rx="3.36" ry="3.36" fill="#ffffff"/>
<rect x="162.11" y="44.50" width="6.71" height="11.00" rx="3.36" ry="3.36" fill="#ffffff"/>
<rect x="174.53" y="27.00" width="6.71" height="46.00" rx="3.36" ry="3.36" fill="#ffffff"/>
<rect x="186.96" y="23.50" width="6.71" height="53.00" rx="3.36" ry="3.36" fill="#ffffff"/>
<rect x="199.38" y="37.50" width="6.71" height="25.00" rx="3.36" ry="3.36" fill="#ffffff"/>
<rect x="211.80" y="37.50" width="6.71" height="25.00" rx="3.36" ry="3.36" fill="#ffffff"/>
<rect x="224.22" y="34.00" width="6.71" height="32.00" rx="3.36" ry="3.36" fill="#ffffff"/>
<rect x="236.64" y="20.00" width="6.71" height="60.00" rx="3.36" ry="3.36" fill="#ffffff"/>
<rect x="249.07" y="41.00" width="6.71" height="18.00" rx="3.36" ry="3.36" fill="#ffffff"/>
<rect x="261.49" y="20.00" width="6.71" height="60.00" rx="3.36" ry="3.36" fill="#ffffff"/>
<rect x="273.91" y="30.50" width="6.71" height="39.00" rx="3.36" ry="3.36" fill="#ffffff"/>
<rect x="286.33" y="23.50" width="6.71" height="53.00" rx="3.36" ry="3.36" fill="#ffffff"/>
<rect x="298.76" y="34.00" width="6.71" height="32.00" rx="3.36" ry="3.36" fill="#ffffff"/>
<rect x="311.18" y="20.00" width="6.71" height="60.00" rx="3.36" ry="3.36" fill="#ffffff"/>
<rect x="323.60" y="41.00" width="6.71" height="18.00" rx="3.36" ry="3.36" fill="#ffffff"/>
<rect x="336.02" y="41.00" width="6.71" height="18.00" rx="3.36" ry="3.36" fill="#ffffff"/>
<rect x="348.44" y="27.00" width="6.71" height="46.00" rx="3.36" ry="3.36" fill="#ffffff"/>
<rect x="360.87" y="23.50" width="6.71" height="53.00" rx="3.36" ry="3.36" fill="#ffffff"/>
<rect x="373.29" y="44.50" width="6.71" height="11.00" rx="3.36" ry="3.36" fill="#ffffff"/>The first and last bar are always the smallest, so these are apparently used for orientation during scanning, as well as the Spotify logo, which is always on the left in the image. Without them, nothing works.

The app turns the number 556205622371746371156 into 58992959842 using Gray code. This makes the recognition very fast and error-resistant. How did we find out? By this point, we had stumbled upon a Spotify patent describing how these codes work.
The last question remains: how does the app turn the concise 58992959842 into spotify:track:5jxN9knH0vlfpN2Ft7a5xi?
Obviously, this number cannot accommodate all the combinations of the long alphanumeric ID, so there's no algorithm, and the correspondence between the code and track ID must be stored somewhere in the database.
We can test this by feeding the generator some very long garbage that would definitely not fit into the number: https://scannables.scdn.co/uri/plain/jpeg/000000/white/640/spotify:track:thisisaverylongidentifierwhichwoulddefinitelyoverflowthatnumericcode
It worked. It's a shame, as it would have been interesting to learn how to encode/decode these images completely independently.
I decided to check the app's communication with the server during recognition, and my guess was confirmed:

Boring: everything else happens behind the backend curtain. So let's move on I guess?
Verylonggarbage
Wait, what? The generator made an image for verylonggarbage?
It probably doesn't validate the input data at all and carefully stores our garbage in the database, assigning it an 11-digit numeric ID.

What happens if you scan such a code with the Spotify app?

This is the expected reaction. The server has most likely already verified and invalidated the incorrect code. It's interesting to see how this error looks, so let's take a look at the traffic one more time:

Splendid. Spotify stores in its database everything we feed to the generator, keeps it there, and returns it in its original form when scanning without any validation.
The idea of turning this into a quest for reverse engineering enthusiasts arose around this point, but it would have been too boring: the error when scanning would have immediately aroused suspicion.
Everything is better with music
To make it look neat, you need to force the app to play music despite the garbage data in the track ID.
I was about to reverse-engineer the obfuscated Android app code to find out how the parser works, but my buddy suggested trying to separate the music ID and our payload with a question mark. The idea worked, but the sign had to be passed through urlencode twice. For example, spotify:track:2ctvdKmETyOzPb2GiJJT53%253Fhi,habr! looks like this:

This code is read by the app as usual and will play the song, but if you look at the traffic, you can fetch the hidden data, which became the core of my quest. For convenience, you can encode the data in Base64━there's plenty of room in the URL.
Conclusions
Why does Spotify allow garbage to be stored in its database?
It's probably because an independent microservice handles the generation and recognition of codes and is supposed to respond instantly. Checking for track existence would require accessing the main backend, which is a resource-intensive task.
Will this harm Spotify?
In theory, this feature allows you to fill up the code correspondence table and exhaust its capacity, breaking the image generation for real tracks, but in practice, it would take a very long time. I did the math.
Is this useful in practice?
I have no idea how this could be useful, unless you are into hiding stuff in the weirdest places. Keep in mind that the API request for reading the code requires a Spotify account authorization token, unlike the request for generating an image.
The original quest was here, and the message was in Base64. Someone passed it in 42 minutes. I didn't expect any more: those used to peeking into app traffic would have guessed immediately.
My buddy El helped think, suggested the possibility of storing codes in the database, and decided to add a question mark to the ID.
UPD: On the morning of September 15, just a day after the publication, Spotify fixed the bug.
The code generator no longer accepts garbage; it now only works with suitable format IDs.
This is very disappointing because I thought they wouldn't care and might even consider it a feature. I could have reached out to Bug Bounty instead :(